GitLab Runner Horizontal Pod Autoscaler
問題描述
當多人在短時間內觸發大量 pipeline 時,就會有的 pipeline 顯示 pending,原因是什麼? 一個 gitlab-runner 有最大可接下的 job 數目限制,例如在 config.toml 設 concurrent = 10,當同時有 11 pipeline 要執行,必然有 1 pipeline pending。
解決的方法
- 第一種是提高 concurrent 值
但就算把 concurrent 拉到非常高,每有新 pipeline 被觸發,亦是由同支 gitlab-runner 先去接應,再把 job 轉交衍生的 concurrent runner,當多人同時觸發大量 pipeline 會造成部分得不到 gitlab-runner 立即關照的 pipeline 直接被 cancel。
- 第二種是提高 gitlab-runner 的數量
但是這麼做在非提交尖峰時段,會有一些 gitlab-runner 閒置而浪費資源,接下來要說明如何透過 HPA 機制改良這種作法。
更進一步解釋
- 可接下的 job 數量
一個 gitlab-runner pod / container 可接受的最大 job 數量設定如concurrent: 10,由這個演算法機制,決定何時增加或結束額外的 concurrent runner pod / container。

- 可增加的 gitlab-runner replicas
HPA 是指當我們用 helm chart 佈好 gitlab runner deployment 之後,由這個演算法機制,決定何時增加或結束 gitlab-runner pod 複本,複本數量的最大和最小值設定如下:
hpa:
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: gitlab_runner_jobs
targetAverageValue: 150m
準備好環境
安裝 GitLab Runner
helm repo add gitlab https://charts.gitlab.io
helm search repo -l gitlab/gitlab-runner
helm install --namespace <NAMESPACE> -f <CONFIG_VALUES_FILE> <RELEASE_NAME> gitlab/gitlab-runner
# <CONFIG_VALUES_FILE>
gitlabUrl: http://your.gitlab.com/
runnerRegistrationToken: "YOUR_PROJECT_TOKEN"
concurrent: 10
runners:
image: docker:18.09
privileged: true
volumes:
- type: "host_path"
name: "docker"
path: "/var/run/docker.sock"
mount_path: "/var/run/docker.sock"
# IPs=$(kubectl get pod -o wide -n 5gc | awk 'NR > 1 {print $6}')
# curl $IPs:9252/metrics
metrics:
enabled: true
rbac:
create: true
hpa:
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: gitlab_runner_jobs
targetAverageValue: 150m
安裝 Prometheus 及 Custom Metrics API Server
我們採用 stefanprodan/k8s-prom-hpa
git clone https://github.com/stefanprodan/k8s-prom-hpa
cd k8s-prom-hpa
kubectl create -f ./namespaces.yaml
kubectl create -f ./prometheus
make certs
kubectl create -f ./custom-metrics-api
測試 metric
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/<YOUR_NAMESPACE>/pods/*/<METRIC_NAME>" | jq
<METRIC_NAME> 可以在 http://<NODE_IP>:31190/ 找到
實驗結果
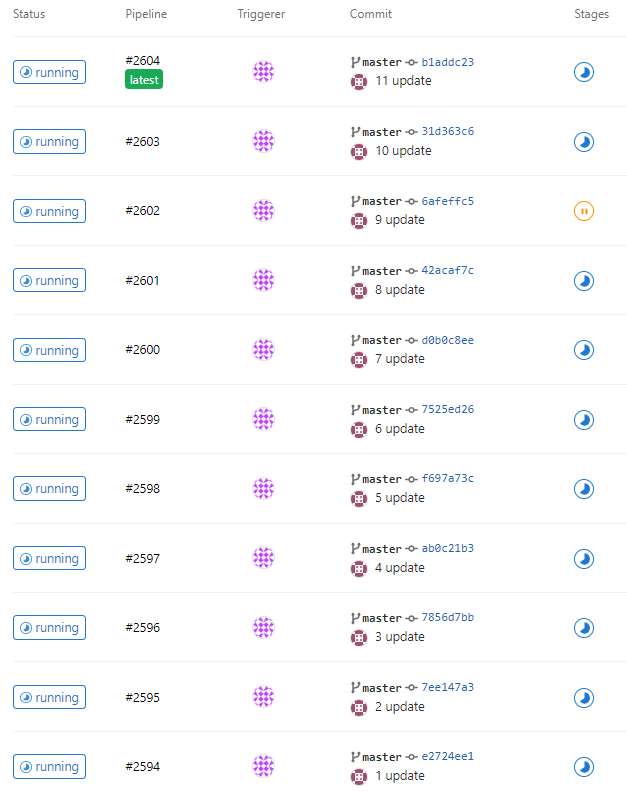
I. 同時觸發 12 個 jobs(可以設每個 job sleep 900,我們要多一點時間觀察 XD)
II. 觀察 hpa
kubectl get hpa -n <YOUR_NAMESPACE>

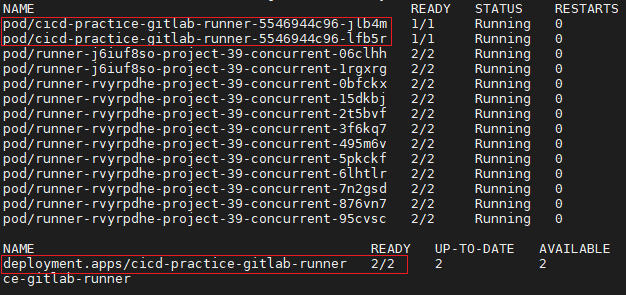
因為 177m 超過我們設定的門檻 150m,所以 gitlab-runner pod 自動增加了

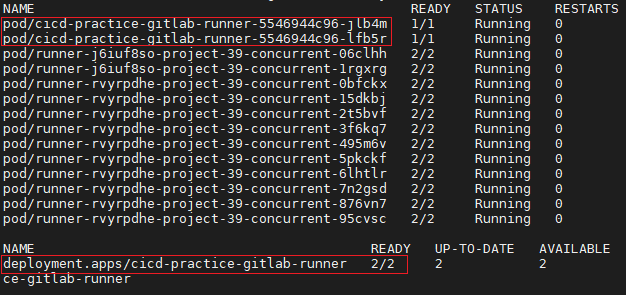
kubectl get all -n <YOUR_NAMESPACE>
III. 觀察 Prometheus
- 用來觀察實驗的 PromQL:
sum(gitlab_runner_jobs{namespace="YOUR_NAMESPACE"})sum(gitlab_runner_version_info{namespace="YOUR_NAMESPACE"})(sum(gitlab_runner_jobs{namespace="YOUR_NAMESPACE"}) / sum(gitlab_runner_concurrent{namespace="YOUR_NAMESPACE"})) / sum(gitlab_runner_version_info{namespace="YOUR_NAMESPACE"})
- 解釋:
gitlab_runner_jobs: 某 gitlab-runner 目前正在執行 job 的數量gitlab_runner_version_info: 有哪些 gitlab-runner podgitlab_runner_concurrent: 某 gitlab-runner 允許接到 job 的最大數量
Here are the results!
- PromQL:
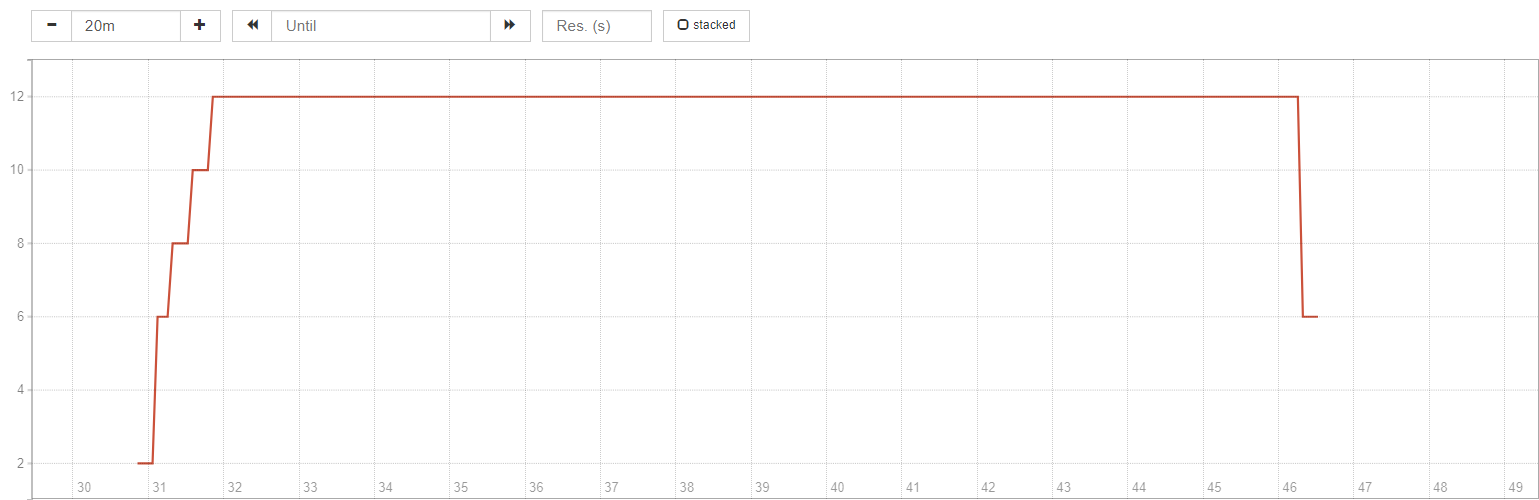
sum(gitlab_runner_jobs{namespace="YOUR_NAMESPACE"})
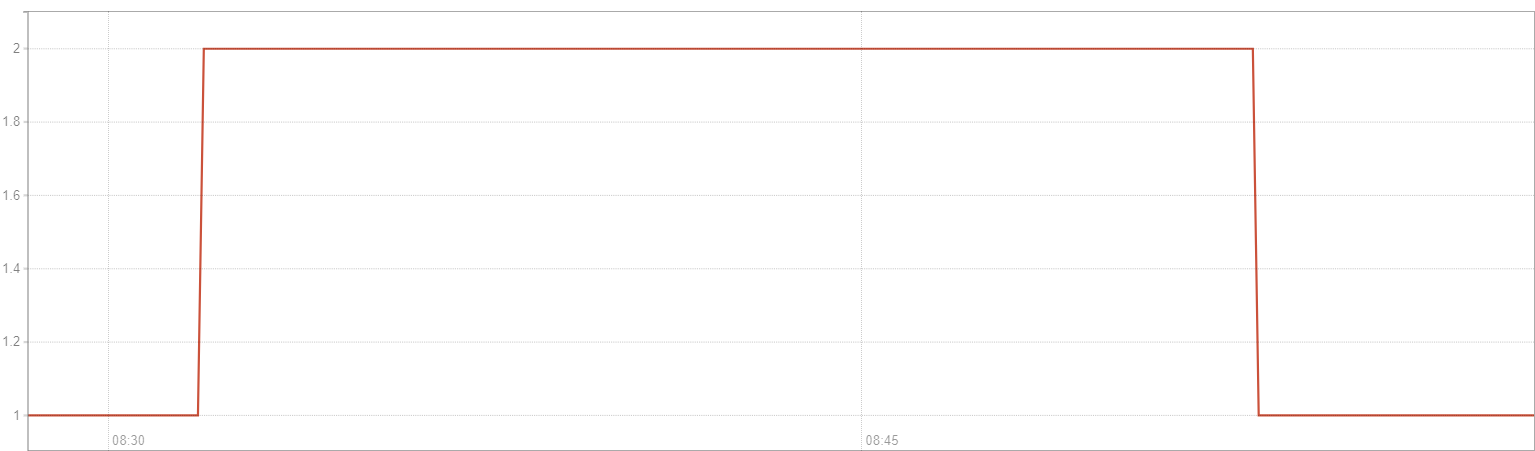
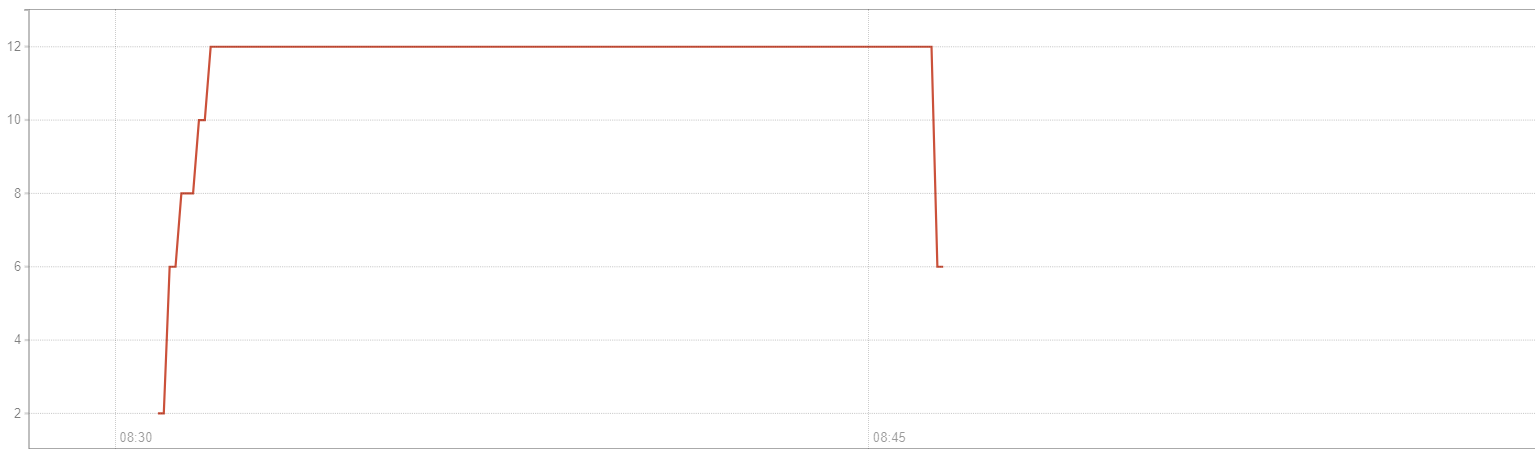
job 數量開始飆到 12
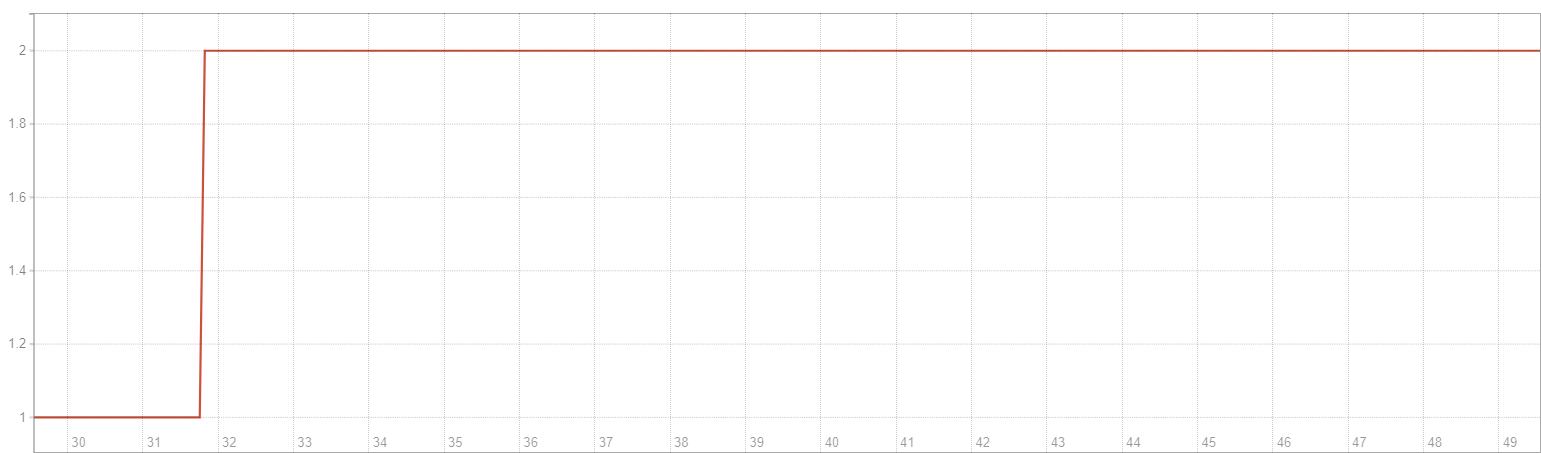
- PromQL:
sum(gitlab_runner_version_info{namespace="YOUR_NAMESPACE"})
因為HPA機制發現 177m 超過 150m,所以幫我們自動生成 gitlab-runner replica,總數量變成 2
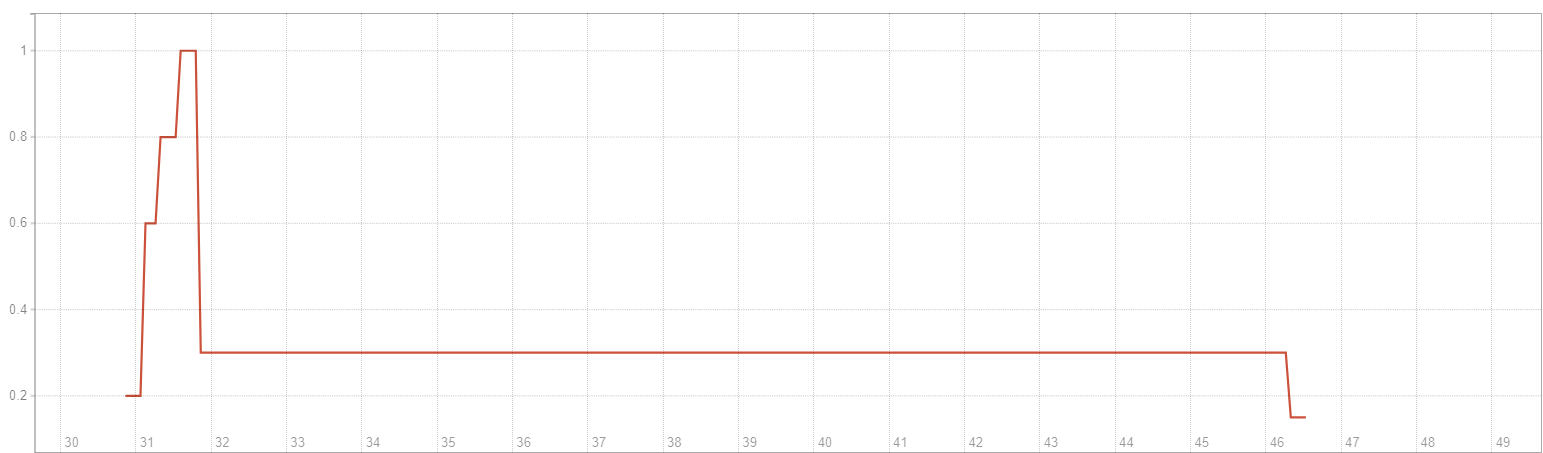
- PromQL:
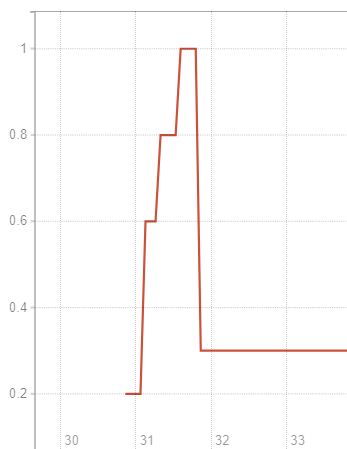
(sum(gitlab_runner_jobs{namespace="YOUR_NAMESPACE"}) / sum(gitlab_runner_concurrent{namespace="YOUR_NAMESPACE"})) / sum(gitlab_runner_version_info{namespace="YOUR_NAMESPACE"})
於是平均一個 gitlab-runner pod 所負責的 job 飽和度陡降
- 最後,HPA機制發現正在執行的 job 已經沒有了,就默默地把 gitlab-runner replica 降成一個就夠了
PromQL: sum(gitlab_runner_jobs{namespace="YOUR_NAMESPACE"})
PromQL: sum(gitlab_runner_version_info{namespace="YOUR_NAMESPACE"})